Hypercane: Toolkit for Summarizing Large Collections of Archived Webpages
Accepted Future Publication
by Shawn M. Jones, Valentina Neblitt-Jones, Michele C. Weigle, Martin Klein, Michael L. Nelson
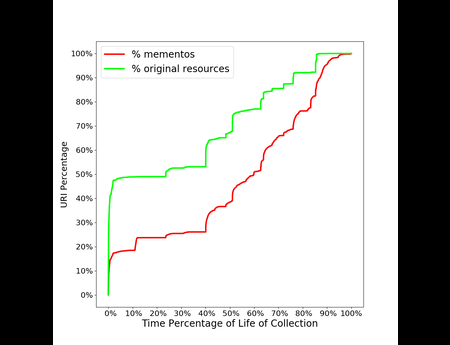
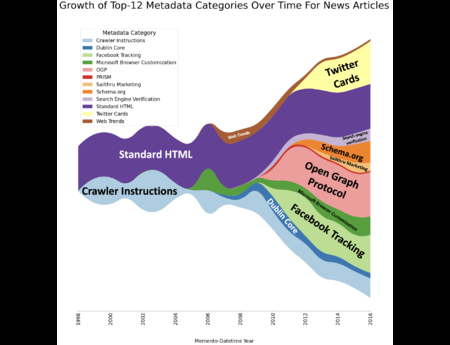
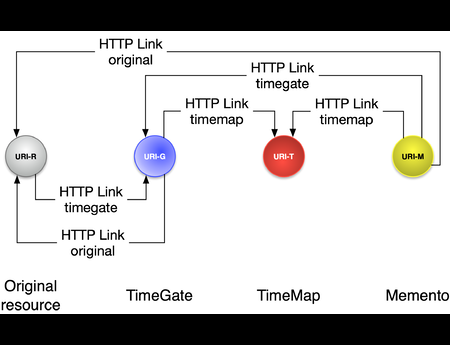
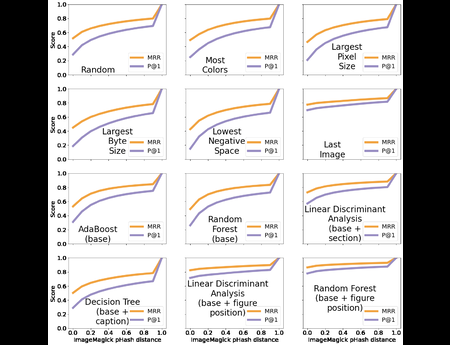
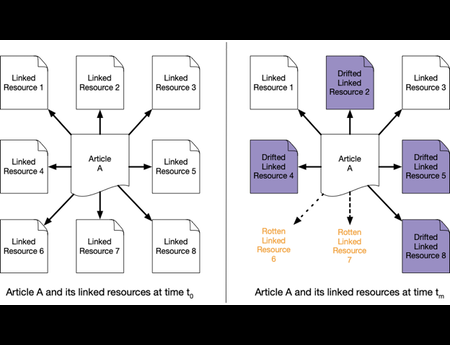
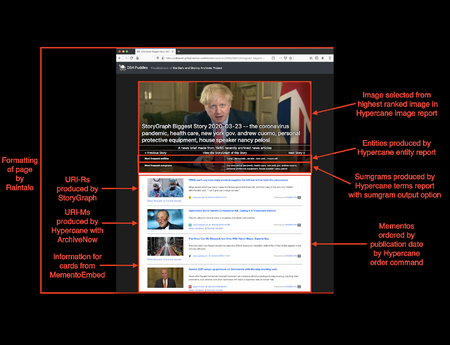
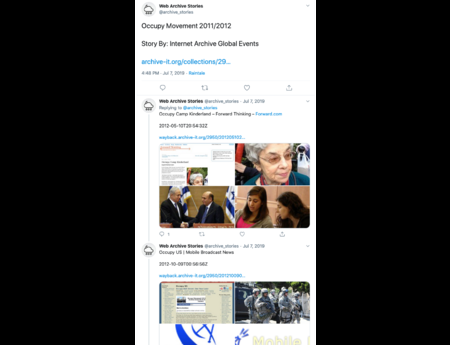
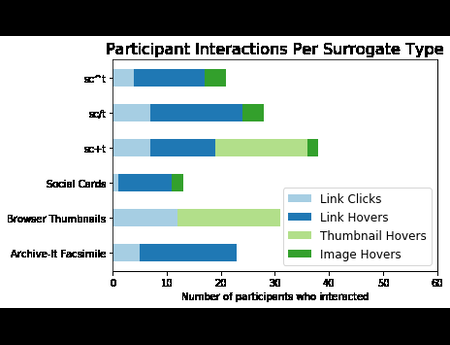
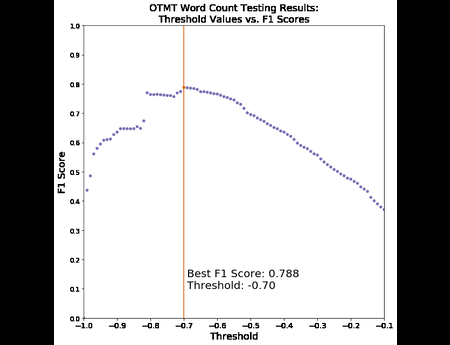
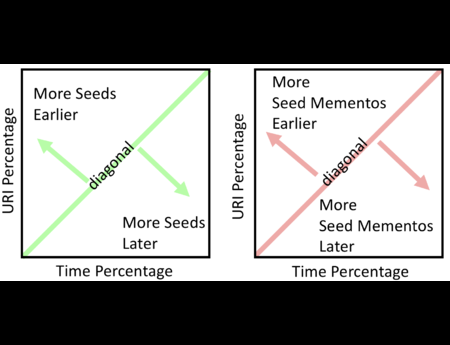
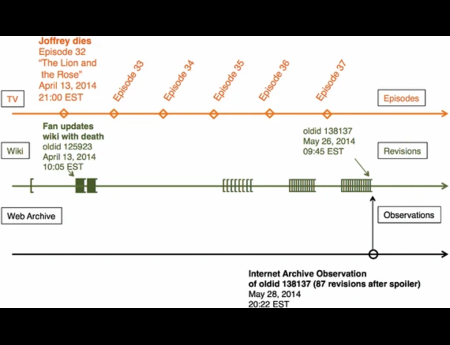
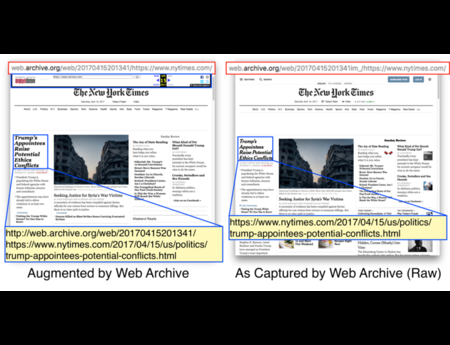
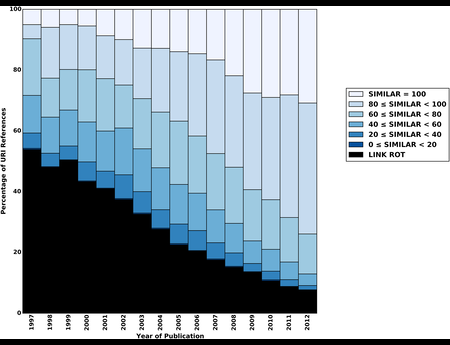
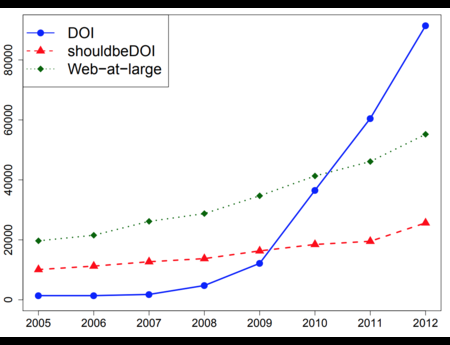
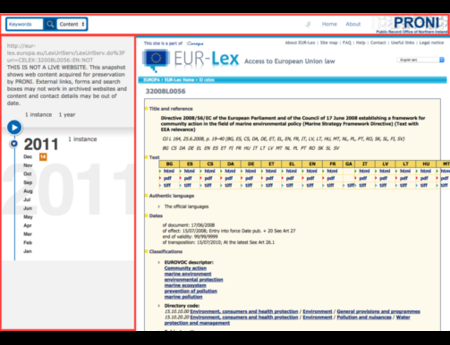
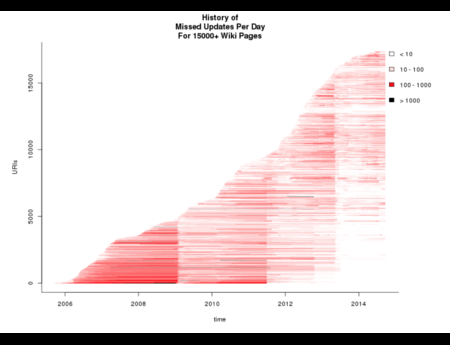
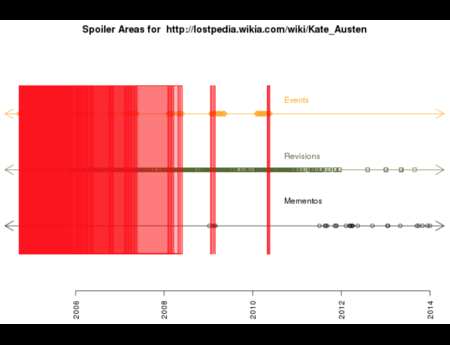
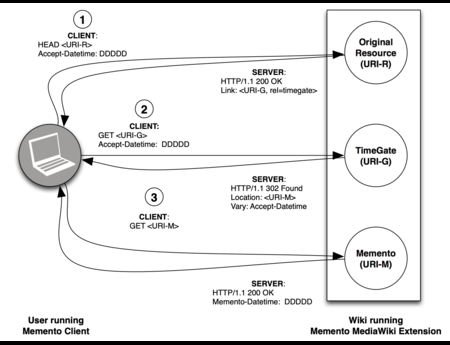
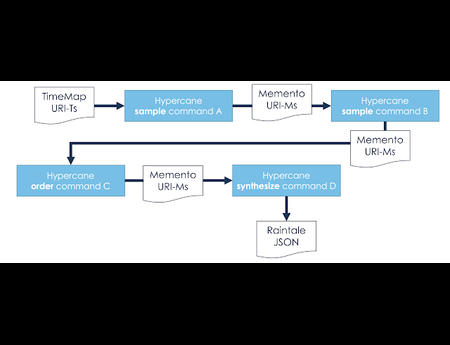
In the Dark and Stormy Archives (DSA) project, we focus on storytelling techniques to summarize collections of archived web pages. Since collections can have hundreds or even thousands of seeds (initial URLs) and each seed can be recrawled many times, with each version separat...